In the previous article we built a template engine that supports streaming. Unfortunately, it did not perform very well when rendering a test page (a blog home page) compared to other popular libraries. In this article, we will look at several techniques that will lead us to a more efficient implementation.
Refresher
Here are the relevant parts of the code we will improve. For more details, please refer to the first part.
// tagged template: ex: html`<p>hello ${name}</p>`
function* html(templateParts, ...values) {
const [first, ...rest] = templateParts;
yield first;
for (const [templatePart, value] of zip(rest, values)) {
if (value?.[Symbol.iterator] && typeof value !== 'string') {
yield* value;
} else if (value?.then) {
yield value;
} else {
yield escape(String(value));
}
yield templatePart;
}
}
// the rendering function: const stream = _render(html`<p>hello ${name}</p>`)
async function* _render(template) {
for (const chunk of template) {
if (typeof chunk === 'string') {
yield chunk;
} else if (chunk?.then) {
yield* _render(await chunk);
} else if (chunk?.[Symbol.iterator]) {
yield* _render(chunk);
} else {
throw new Error('Unsupported chunk');
}
}
}Diagnostic
If you generate a flame graph of the load test, you will get the following figure:
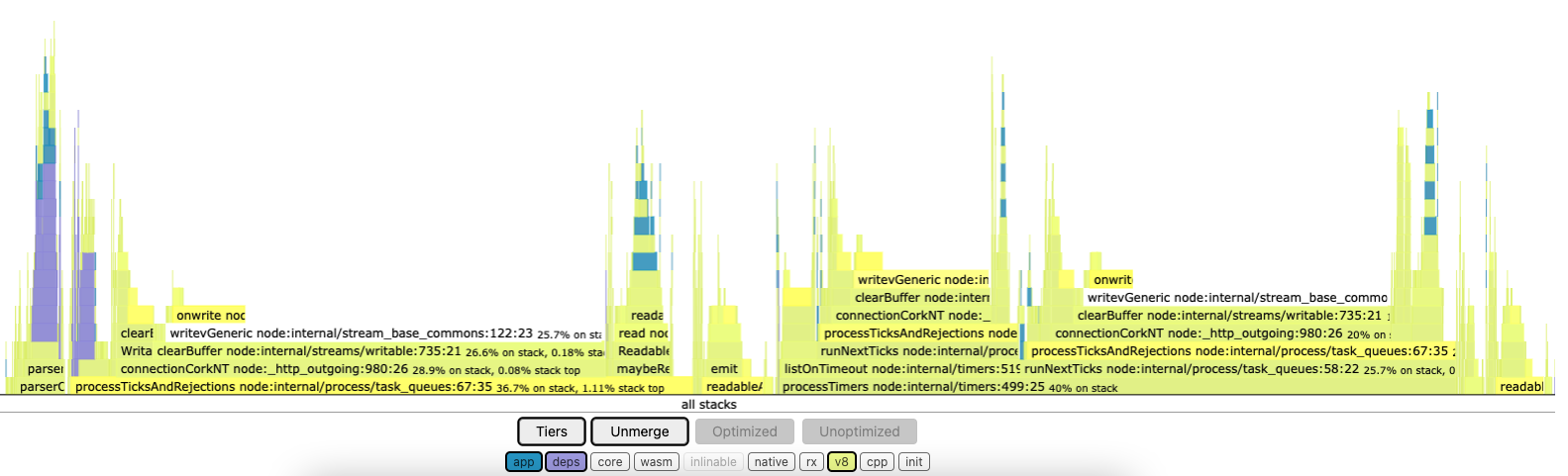
You can see that the process actually spends very little time in the application code (in blue). Most of the CPU is used in the v8 code, and particularly in the code dealing with the task/micro-task queues.
To be honest, I am not entirely sure how to interpret this graph. But if you track the memory allocation, or simply add a log whenever a chunk is emitted by the _render async generator, you will see that a lot of Promises are being created.
In practice, rendering the page once generates 87 chunks (and as many Promises) whereas there is only one Promise to wait for in order to fetch all the data (the one that gets the post list).
Let’s see our we can reduce this amount and check whether it improves the performances of the template engine.
Just In Time compilation (JIT)
If you take the basic template:
const Greet = ({name}) => html`<p>hello ${name}</p>`;The sequence generated will be equivalent to the one created by
function *Greet({name}) {
yield `<p>`;
yield escape(String(name));
yield `</p>`;
}which has three items that will eventually become as many asynchronous chunks in the _render function. That is a shame as we could simply generate one item with:
function *Greet({name}) {
yield `<p>${escape(String(name))}</p>`;
}What if we could create the template Greet function on the fly ? Actually, yes we can. The process of compiling code while the program is already running is called just-in-time compilation (JIT).
For a basic function, you can simply use the Function constructor and pass the list of bindings (parameters) together with the actual source code of the function:
const sum = new Function('a', 'b', 'return a + b');
console.log(sum(2, 6));
// Expected output: 8You can do the same with generator functions, although the constructor is not global:
const { constructor: GeneratorFunction } = function* () {};And then compile the template functions:
const templateCache = new WeakMap();
function html(templateParts, ...values) {
if (!templateCache.has(templateParts)) {
templateCache.set(templateParts, compile(templateParts, ...values));
}
return templateCache.get(templateParts)(...values);
}
const compile = (templateParts, ...values) => {
const src = buildSource(templateParts, ...values);
const args = [
'utils',
...Array.from({ length: values.length }, (_, i) => 'arg' + i)
];
const gen = new GeneratorFunction(...args, src);
return (...values) => gen({ escape }, ...values);
};We use a WeakMap to cache the compiled functions to ensure that each template is compiled once and only once because this is a costly operation.
The compiled functions have as many parameters as there are values to interpolate, and we create a binding named arg{index} for each of them.
In addition to these parameters, the first argument will be an object of some utility functions (like escape) so that we can use them in the source code we are about to generate:
const buildSource = (templateParts, ...values) => {
const [first, ...rest] = templateParts;
const tuples = zip(rest, values);
return (
tuples.reduce((src, [tplPart, value], i) => {
if (value?.[Symbol.iterator] && typeof value !== 'string') {
return src + `;yield *arg${i};yield \`${tplPart}\``;
}
if (isAsync(value)) {
return src + `;yield arg${i}; yield \`${tplPart}\``;
}
return src + `+utils.escape(String(arg${i})) + \`${tplPart}\``;
}, `yield \`${first}\``) + ';'
);
};The source code is a simple concatenation of strings until we hit an iterable or async value. In this case, we complete the concatenation (see the semicolon prefix) and we yield the non-literal value.
This change already improves performance significantly: the server is now able to handle 823(instead of 238) requests per second and the library already outperforms the ejs template engine.
On the other hand, we now log only 15 chunks.
Avoid Promise overhead
Async functions introduce an overhead that can usually be disregarded. In our case this is a bit different as the penalty increases with the complexity of the template we are trying to render.
Moreover, we use async constructs for the convenience of their control flows, but they are semantically a bit different from what we want to achieve and waste resources by creating unnecessary Promises. Again, in the test page there is only one async call to wait for (to fetch the posts data).
Ideally we would like to have a main synchronous function that delegates the control to an async function only when it is necessary, but this is impossible with async functions.
Especially here, where we have a recursion: the _render function has to be async all the way, even though it deals with synchronous execution most of the time.
There is a solution: we can think of _render as a recursive coroutine!
function* _render(template, controller) {
for (const chunk of template) {
if (typeof chunk === 'string') {
controller.enqueue(chunk);
} else if (chunk?.[Symbol.iterator]) {
yield* _render(chunk, controller); // delegation !
} else if (chunk?.then) {
const resolved = yield chunk; // pauses only when necessary
if (typeof resolved === 'string') {
controller.enqueue(resolved);
} else {
yield* _render(resolved, controller); // delegation !
}
} else {
throw new Error('Unsupported chunk');
}
}
}The _render function is now synchronous and takes the stream controller as a parameter. We enqueue the chunks when they are ready and no longer yield anything except Promises.
This has the effect of pausing the routine while waiting for the caller to resume the execution once the asynchronous value is available.
The caller is the ReadableStream itself, and there is no need to pass through an async generator that was creating a lot of useless Promises:
function render(template) {
return new ReadableStream({
start(controller) {
const iterable = _render(template, controller);
return pump();
async function pump(chunk) {
const { value } = iterable.next(chunk);
if (value?.then) {
const asyncChunk = await value;
return pump(asyncChunk);
}
controller.close();
}
},
});
}It passes its internal controller to the _render routine, which is executed until it pauses (when a Promise is yielded).
It can wait for that Promise to be resolved and then resume the execution of the routine, passing the resolved value.
controller.enqueue is still called 14 times, but the async pump function is only called twice, and we have improved the performances even more: the server can now handle 944 requests per second.
Buffer chunks
Calling the internal ReadableStream controller enqueuing function 14 times can seem harmless, but it is not.
I must admit that I was surprised when I experienced this, as I thought Node would be able to optimise its implementation, but apparently not.
I have already planned to dig in the source code.
We can change our strategy: let’s buffer strings together until there is a Promise (which we have to wait for anyway) and enqueue the buffered data at that moment. All we have to do is change the render function:
function render(template) {
return new ReadableStream({
start(controller) {
const buffer = [];
const iterable = _render(template, {
enqueue: (val) => buffer.push(val), // we pass our own "controller" instead
});
return pump();
async function pump(chunk) {
const { value } = iterable.next(chunk);
if (value?.then) {
if (buffer.length) {
controller.enqueue(buffer.join('')); // enqueue at that moment
}
const asyncChunk = await value;
buffer.length = 0; // empty buffer
return pump(asyncChunk);
}
// if left over
if (buffer.length) {
controller.enqueue(buffer.join(''));
}
controller.close();
}
},
});
}And we are now performing almost as well as Pug with a server that can handle 1550 requests per second!
Conclusion
We went through three different techniques to optimise the template engine, and we now have very good performance on the test case. Performance is not the only criterion: after all, EJS is downloaded 13 million times a week, yet it performs poorly compared to Pug and tpl-stream(the library we built). Given its popularity, we can assume that the EJS’s performance is good enough for the vast majority of people and use cases.
tpl-stream is very flexible, as it stands on Javascript tagged templates. It has no build step involved, and a small (yet fairly easy to read) code base with no particular obfuscation to get even more performance gains. In the browser, you will only have to download 935 bytes to get the library (minified and gzipped), while the install size with npm is about 10kb; in order words, it is 600 times smaller than the size of Pug! All this makes the library pleasant to work with and easy to maintain, which are other important advantages, at least in my opinion.