Pub/Sub is a common pattern for distributed - or not - systems. It provides the ability to reduce the coupling between the event producer on one side and the event consumer on the other. We often associate this pattern with event streaming technologies such as Kafka, but this does not have to be the case: Postgres can help you achieve decent scalability, depending on the use case.
The business case
You are starting a new business dealing with financial transactions. For some reason (traceability, for example), you
have decided to store all the business facts that happen to the transactions.
Instead of having a transactions table that holds the current state of the transactions, you would rather have a
transaction_events table with all the recorded business events on transactions:
| position | transaction_id | event_type | payload | version |
|---|---|---|---|---|
| 1 | transaction_a | initiated | { “amount” : 42_00, date: “2025-02-09”} | 1 |
| 2 | transaction_b | initiated | { “amount” : 31_00, date: “2025-02-08”} | 1 |
| 3 | transaction_a | authorized | { “authority”: “some_bank”} | 2 |
| 4 | transaction_c | initiated | { “amount” : 20_00, date: “2025-02-09”} | 1 |
| 5 | transaction_b | rejected | { “authority”: “some_bank” } | 2 |
- position is the global position of the event (ie transaction independent)
- transaction_id is a unique identifier of a transaction (which can have more than one event associated)
- version is the transaction version after a specific event has been recorded for that transaction
This table is append only. Once an event has been recorded, it can’t be modified: it is the source of truth of all what happened in your system.
When you look more closely at this table, you realize it is actually a key/value store whose keys are the transaction ids and the values all the events associated to a specific transaction:
const transactions = {
transaction_a: [{eventType: 'iniated' /* .. */}, {eventType: 'authorized', /* .. */}],
transaction_b: [{eventType: 'iniated' /* .. */}, {eventType: 'rejected', /* .. */}],
transaction_c: [{eventType: 'iniated' /* .. */}]
}
So that, at any time, by reducing the events, you are able to define the current state of a given transaction:
const transactionA = {
transactionId: 'transaction_a',
status: 'authorized',
amount: 42_00,
date: '2025-02-09',
authority: 'some_bank',
version: 2
}This is fine for the first few months and for most use cases. But as the business becomes more successful, it becomes more complicated to answer questions such as "What are all the transactions authorised by authority “Bank A”? The key/value store starts to show its limitations
This is not necessarily a big deal: you can build a read model designed for this specific use case:
| transaction_id | status | amount | date | authority | version |
|---|---|---|---|---|---|
| transaction_a | authorized | 42_00 | 2025-02-09 | some_bank | 2 |
| transaction_b | rejected | 31_00 | 2025-02-08 | some_bank | 2 |
| transaction_c | initiated | 10_00 | 2025-02-09 | null | 1 |
With the right indexing strategy, it will give you acceptable performance for most of the questions you can ask about the current state of transactions. Of course, you have to maintain this read model, but because we are using Postgres, we can perform any write operation on this model within the same database transaction that produces the event, which guarantees strong consistency.
A few months go by, and again you have new requirements: not only do you have to maintain the read model, but every time a transaction is initiated, you have to trigger a background job for fraud detection. You also need to maintain a consolidated analytics view, etc. You understand: you cannot cram all this logic into the same database transaction and you need to decouple all this processing.
Postgres logical replication
You have decided that decoupling the publication of the event from its processing is the way to go and have started looking at various pub/sub systems (Kafka, RabbitMQ, Google pub/sub, etc.). You are a little puzzled by the challenges of running these systems, especially as you do not have the skills in-house. Fear not, you can simply use Postgres logical replication.
This is a built-in mechanism that works by publishing the logical operations that take place in the database. In our
case, this could be notification whenever a new row is appended to the transactions_events table.
It relies on Write-Ahead logging, a standard method of
ensuring data integrity. It consists in writing data changes to a log before flushing the new data pages to disk and
reducing the disk accesses. In the event of a failure,
the system only needs to replay these logical operations to recover the current state of the database.
The WAL is an ephemeral structure that disappears when all subscriptions to a given publication have confirmed that they have received the messages. This is not a problem in the sense that it means that the data has been safely persisted to the various tables and consumed by the subscribers.
Without going into too much detail, we need to change the Postgres configuration to allow logical replication:
# pg.conf
wal_level = logicaland create a publication for the relevant table:
CREATE PUBLICATION test_publication FOR TABLE ONLY transaction_events WITH (publish ='insert');You can now subscribe to the insertion of rows into the transaction_events table.
Code-wise, there is nothing else to do on the publishing side, and we have a system with the following properties:
- Persistence and Durability: as the source of the events is a regular table, we have the same guarantees of data integrity that Postgres provides.
- Message ordering: the WAL records all the transactions as they are committed, so that the column
positiongives us global ordering. - Message delivery guarantees: by design, we have the guarantee that a message will be delivered at least once ( that’s sort of the purpose of the WAL), and messages are kept in the WAL until subscribers have acknowledged receipt of the messages (this can lead to WAL file bloat if you don’t handle subscription lifecycles properly).
- Regarding the performances (throughput and latency) we are going to conduct some experiments, but the TLDR; is that the system is quite sufficient for the expected OLTP load of our platform.
Subscribing to new events
To subscribe to a publication, we have to either create a subscription (mostly used for replication between different databases) or manually manage a replication slot:
SELECT *
FROM pg_create_logical_replication_slot('test_slot', 'pgoutput'); -- pgoutput is the plugin to decode the messagesOnce the slot is created, we should connect a client that handles the logical streaming replication protocol to the database server, and decode the messages as they arrive in order to process them.
We will be using an existing library for that and wrap it so we can provide a streaming API:
import {Readable} from 'node:stream';
import {
LogicalReplicationService,
PgoutputPlugin,
} from 'pg-logical-replication';
export class LogicalReplicationStream extends Readable {
#source;
#lastLsn;
#decoder;
#slotName;
constructor({
highWaterMark = 200,
publicationName,
clientConfig,
slotName,
onError = console.error,
})
{
super({highWaterMark, objectMode: true});
const replicationService = (this.#source = new LogicalReplicationService(
clientConfig,
{
acknowledge: {auto: false, timeoutSeconds: 0},
},
));
this.#slotName = slotName;
this.#decoder = new PgoutputPlugin({
protoVersion: 4,
binary: true,
publicationNames: [publicationName],
});
this.#source.on('data', async (lsn, message) => {
if (!this.push({lsn, message})) {
await replicationService.stop();
}
await this.acknowledge(lsn);
});
this.#source.on('error', onError);
this.#source.on('heartbeat', async (lsn, timestamp, shouldRespond) => {
if (shouldRespond) await this.acknowledge(lsn);
});
}
_read() {
if (this.#source.isStop()) {
this.#source.subscribe(this.#decoder, this.#slotName, this.#lastLsn);
}
}
async acknowledge(lsn) {
this.#lastLsn = lsn;
await this.#source.acknowledge(lsn);
}
}It is a Readable stream we set in object mode. The underlying source is a logical replication service provided by the
aforementioned library.
We set up the different listeners: whenever the underlying source sends a new message, we push it into the internal
stream buffer. We then acknowledge the reception of the message.
It the internal queue is full, we need to handle backpressure (if this.push(data) returns false) by pausing the
subscription until the consumer can handle more data, and the _read function is called again.
Now we have the possibility to read the event stream:
const stream = new LogicalReplicationStream({
subscriptionName,
publicationName: 'test_publication',
slotName: 'test_slot',
clientConfig,
});
for await (const message of stream) {
console.log(message)
}Whenever a new event is appended to the table, this program will output
{
lsn: '0/1916E98',
message: {
tag: 'begin',
commitLsn: '00000000/01916FE0',
commitTime: 1740934214433862n,
xid: 752
}
}
{
lsn: '0/1916E98',
message: {
tag: 'insert',
relation: {
tag: 'relation',
relationOid: 16386,
schema: 'public',
name: 'transaction_events',
replicaIdentity: 'default',
columns: [Array],
keyColumns: [Array]
},
new: [Object: null prototype] {
position: '10',
event_type: 'initiated',
transaction_id: 'R5rReE9dHkvQo8RSqJxX1',
payload: [Object],
version: 1,
created_at: 2025-03-02T16:50:14.433Z
}
}
{
lsn: '0/1917010',
message: {
tag: 'commit',
flags: 0,
commitLsn: '00000000/01916FE0',
commitEndLsn: '00000000/01917010',
commitTime: 1740934214433862n
}
}
The triplet covers the whole database operation: the actual database insert (in the middle), together with the transaction begin and commit phases. Each message has its own lsn (log sequence number), but you can see the set as a whole.
As we have a stream API, it is fairly easy to filter, group, map, etc. messages with async generators for example. We can for example group all the events recorded in the same database transaction into a single message and wrap our subscription:
export const createSubscription = ({
subscriptionName,
clientConfig,
handler,
}) => {
const stream = new LogicalReplicationStream({
subscriptionName,
publicationName: 'test_publication',
slotName: 'test_slot',
clientConfig,
});
return {
async listen() {
for await (const transaction of groupByTransaction(stream)) {
try {
await handler({ transaction });
await stream.acknowledge(transaction.commitEndLsn);
} catch (err) {
console.error(err);
}
}
},
};
};
async function* groupByTransaction(stream) {
let currentTransaction = {};
for await (const { message } of stream) {
if (message.tag === 'begin') {
currentTransaction = {
commitLsn: message.commitLsn,
events: [],
xid: message.xid,
};
}
if (message.tag === 'insert') {
currentTransaction.events.push(message.new);
}
if (message.tag === 'commit') {
const replicationLagMs = Date.now() - Number(message.commitTime / 1000n);
currentTransaction.commitEndLsn = message.commitEndLsn;
currentTransaction.replicationLagMs = replicationLagMs;
yield currentTransaction;
}
}
}This can be helpful if you want to handle in a different way, a database transaction with many events (probably related to data ingestion), and a database operation with only a handful of events.
By design, the WAL doesn’t generate nested database transaction messages. You may also notice that the message is now only acknowledged if it has been processed by the subscriber.
Load test
In the future, we assume an OLTP load (small short database transactions) of a few hundred messages by second. Let’s see how our system will cope with this load, by tracking the lag time between the event production and the time the read model is updated.
Our subscriber can be:
import opentelemetry, { ValueType } from '@opentelemetry/api';
// ...
const subscriptionMeter = opentelemetry.metrics.getMeter('subscription');
// we create a metric for the lag
const lag = subscriptionMeter.createHistogram('subscription.events.lag', {
description:
'duration between the commit time of a transaction and the processing by the subscription',
unit: 'ms',
valueType: ValueType.INT,
});
const subscription = createSubscription({
subscriptionName: 'test_slot',
clientConfig,
handler: transactionHandler,
});
await subscription.listen();
async function transactionHandler({ transaction: dbTransaction }) {
const { events } = dbTransaction;
await Promise.all(
events.map(async ({ transaction_id: transactionId }) => {
const transaction = await getTransaction({transactionId});
await saveReadTransaction({transaction});
}));
// update the metric
lag.record(dbTransaction.replicationLagMs);
}where getTransaction would be a function to read all events associated with a given transaction_id from the event store and fold them into the current transaction state.
saveReadTransaction would be:
export const saveReadTransaction =
({ transaction }) => {
const {
transactionId,
status,
version,
date,
authority = null,
amount,
} = transaction;
return db.query(SQL`
MERGE INTO transactions t
USING (VALUES (
${transactionId},
${status},
${version}::integer,
${authority},
${date}::timestamp,
${amount}::float)) AS source(transaction_id, status, version, authority, date, amount)
ON source.transaction_id = t.transaction_id
WHEN MATCHED AND source.version > t.version THEN
UPDATE SET
version = source.version,
status = source.status,
authority = source.authority,
date = source.date,
amount = source.amount
WHEN NOT MATCHED THEN
INSERT (transaction_id, status, version, authority, date, amount)
VALUES (source.transaction_id, source.status, source.version, source.authority, source.date, source.amount)
`);
};A merge query that creates a new row in the read model if there is none for the given transaction_id, or updates the existing one if we have a newer version.
Of course we could have written the same logic in Javascript but I find the SQL merge solution quite appropriate for such use cases.
It is important to note that by first retrieving the transaction from the event store and then using a SQL merge query, our subscription handler is idempotent. This gives us more robustness when it comes to replaying events (remember, we have at least once delivery guarantee) or if we have missed an event for some reason.
On the publisher side we will simply insert a new event (corresponding to the initialisation of a new transaction) at most every 10ms, during 20 minutes, and track the number of events inserted:
const signal = AbortSignal.timeout(1_000 * 60 * 20);
const db = createPool({
...clientConfig,
signal,
});
const eventStore = createEventStore({ db });
while (!signal.aborted) {
await eventStore.appendEvent({
events: [
{
type: 'initiated',
version: 1,
transactionId: nanoid(),
payload: {
amount: faker.finance.amount(),
date: faker.date.recent(),
},
},
],
});
await setTimeout(Math.ceil(Math.random() * 10));
eventCounter.add(1);
}Let’s have a look at the telemetry results:
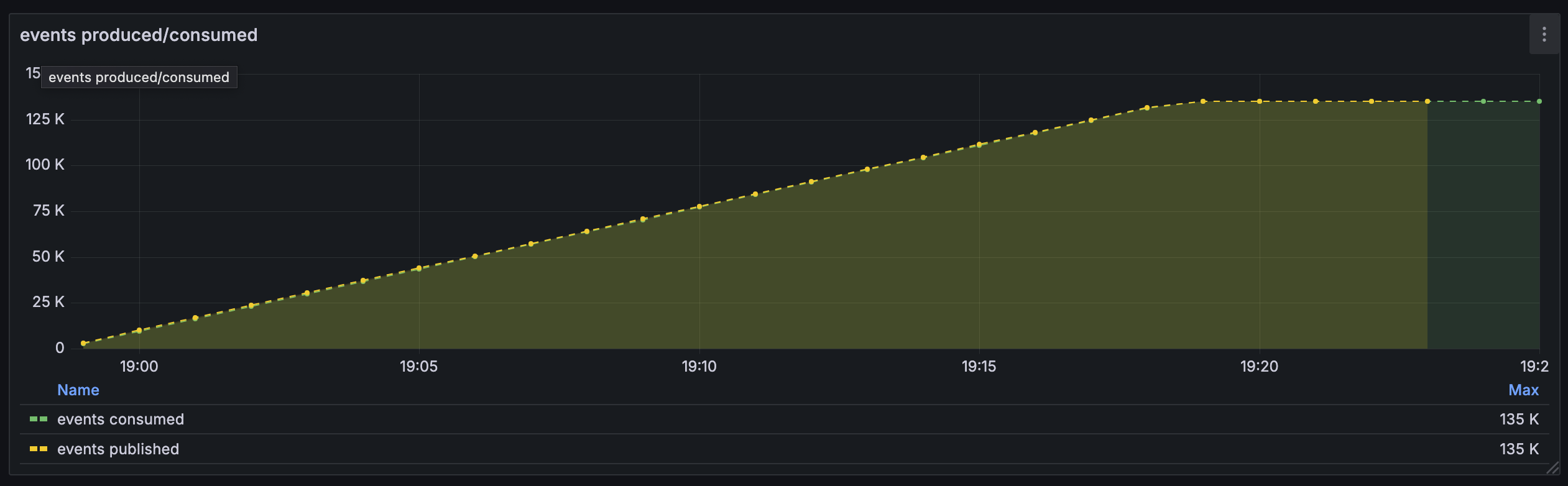
The system was able to ingest around 135k events with a steady ingestion rate. We don’t see any gap between publication and subscription.
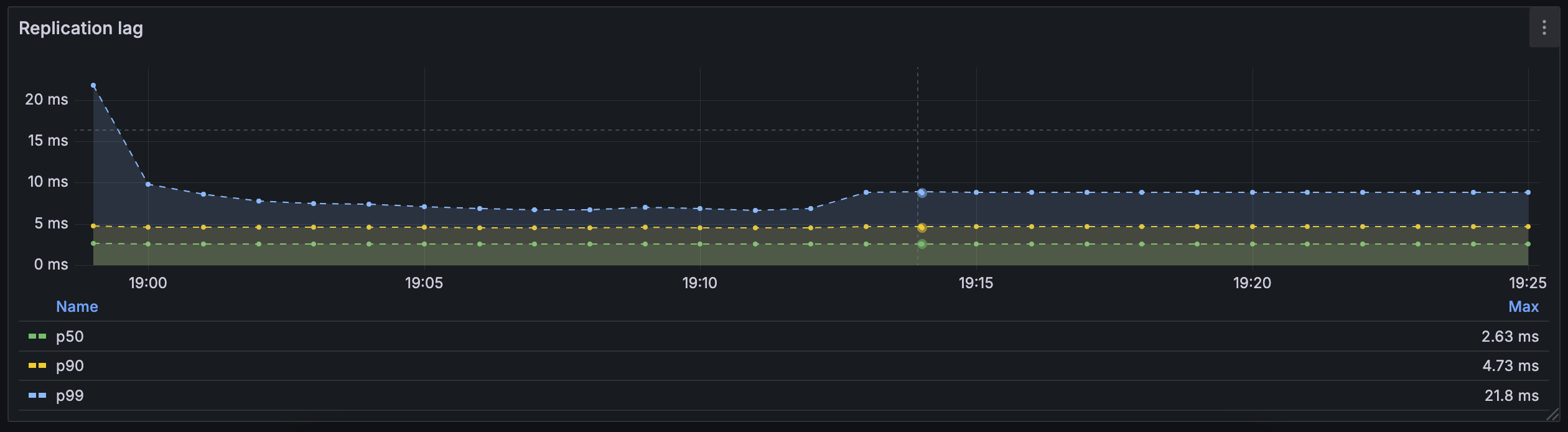
With a p99 of 20ms at most, we can consider the data in the read model to be consistent with the source of truth (the event store): when an event is created, the read model is up to date at most 20ms after ingestion. The replication does not lag behind the production of the events and the WAL can be purged by Postgres on a regular basis avoiding any file bloat.
This is obviously a simulation with some caveats:
- we only have one subscription
- we have not simulated spikes in the load
- we only consider the “initialisation” event
- there is no concurrency
On the other hand, the database is running in a Docker container on an old machine (MacBook Pro early 2015 - 2.7 GHz Dual-Core Intel Core i5 - 8 GB RAM) and could easily handle the expected load without any special tuning.
This means that before Postgres becomes the bottleneck of the system, the business will probably be quite profitable and we should be able to hire a better architect than me :)!
If you wish to run your own simulations you can use this repository as base project
Conclusion
Postgres (and NodeJS) once again proved to be a versatile tool, allowing us to implement a robust pub/sub system with very little effort (none on the publishing side!). We have set up the basics of a protocol to see if this can be scaled up sufficiently. However, we have not delved too deeply into the details and could follow up with some investigations in further posts. For example, we could see how to safely perform the first synchronisation between the event store and a new reading model, since the WAL will only produce record up to a certain point in time.